DIY Autonomous Cars 101: Developing a Driving AI Agent
In this article, we are going to cover how to build an AI driving agent for a car.
You got a car, you know where to go using the GPS waypoints, the car has camera which can see the oncoming traffic and the traffic signal. These things, we have assumed we have. Now, using this information, can the car navigate and reach it’s destination on it’s own? Not really. We need to add some logic, which the car will use, to drive properly. There can be multiple ways to do this. One is by hard coding it. But that’s really old school. There are many drawbacks in doing that, but we are not going to discuss those here. Everything is smart today, so our behavioral scheme should also be smart. We will put some intelligence in it, artificial intelligence that is. And we will let the car learn on it’s own about reaching it’s final destination.
Another thing we have to consider here is we are not going to use an actual car for doing this for two reasons. First is that we are too poor to actually afford a car and another is it is always better to run it on a simulator before putting it in the real world to avoid any never seen before issues. For experimenting this, we are going to use a simulator provided by Udacity. Do check their Machine Learning course if you can, it’s totally worth it. The simulator is written in pygame and it looks like the one shown below

The simulator is on a grid of roads. The roads intersect each other. There are signals on each intersection and the cars are moving randomly but are following the rules of the road. You start with this agent, that is the car that you want to control, and you have been given waypoints to the final destination which is shown by the sign U. Using this information, we will see how to make a driving agent.
We are going to use states to train the smart cab to move randomly and then learn from its actions. A greedy epsilon approach we are going to use to train it. What this approach is? I will tell you in a minute. But let’s first see what these states are. Imagine that you are standing on a road, you see a red signal, that means you are in a certain state. The signal turns green and then it means the state has been changed to something else.
Let’s first see how to define each state,
The first requirement is that states has to be limited, so it is important to consider the factors involved. For example, in this case the signals are good enough states and are directly relevant. But we should not include the time of the day as the state as the possibilities are more and which increases the number of combinations by factor of N. Here, we are considering the following states.
state = (light,waypoint,right,left,oncoming)
Here, light = Traffic light status, waypoint is the next step given by the GPS, right, left and oncoming are the traffics coming from those directions (1 is for present, 0 is for absent)
The Car agent has to follow a certain rules, and those rules are also supposed to be defined. We can add a penalty based function which will penalize the car agent for taking wrong actions for certain states. The agent is driving on its own or using it’s own logic, it is thus rewarded as follows,
# Agent wants to drive forward:
if action == 'forward':
if light != 'green': # Running red light
violation = 2 # Major violation
if inputs['left'] == 'forward' or inputs['right'] == 'forward': # Cross traffic
violation = 4 # Accident
# Agent wants to drive left:
elif action == 'left':
if light != 'green': # Running a red light
violation = 2 # Major violation
if inputs['left'] == 'forward' or inputs['right'] == 'forward': # Cross traffic
violation = 4 # Accident
elif inputs['oncoming'] == 'right': # Oncoming car turning right
violation = 4 # Accident
else: # Green light
if inputs['oncoming'] == 'right' or inputs['oncoming'] == 'forward': # Incoming traffic
violation = 3 # Accident
else: # Valid move!
heading = (heading[1], -heading[0])
# Agent wants to drive right:
elif action == 'right':
if light != 'green' and inputs['left'] == 'forward': # Cross traffic
violation = 3 # Accident
else: # Valid move!
heading = (-heading[1], heading[0])
# Agent wants to perform no action:
elif action == None:
if light == 'green' and inputs['oncoming'] != 'left': # No oncoming traffic
violation = 1 # Minor violation
This is a cost function that we are going to use to force the driving agent to not take actions that will cause the violations. Now as we have defined the states and the rules/violations, we can push the car into the learning process.
The learning process is divided into two sections. Exploration and Exploitation. Now, the exploration takes a lot of time and errors to actually learn the process and thus it is better to do this in a simulator than in the actual world. In simple terms, exploration will happen randomly and again and again. For different states, the car will take random actions and move without any logic. This locomotion will take good and bad decisions and by this the car will know if it is taking good action or not for the certain state. With time, the car will reduce the number of random actions with now the actions that it has learned. Thus we will be seeing the car giving better results with time. To do this, we will be using a Greedy epsilon technique with a Q-learning approach.
While moving randomly, the car is going to visit different states, it will take some action, and by its action it will get either a reward or the penalty. For each step, we are going to store it in a table. It goes as below,
{ 'state-1': { 'action-1' : Qvalue-1, 'action-2' : Qvalue-2, ... }, 'state-2': { 'action-1' : Qvalue-1, ... }, ... }
Sane state can be visited N number of times and different action is taken at initial exploration stage. This, depending on the reward or penalty will give us a Qvalue, we will start storing this value in a table. This is how we calculate the Q-value for that certain action in that certain state.
self.Q[state][action] = (1 – alpha)*self.Q[state][action] + alpha*(reward)
For the state-action pair, depending on the alpha, which is the learning rate, the Q-value is improved if reward or the Q-value goes down in the case of penalty. The epsilon is the probability by which the random action is taken, Initially, the epsilon is 1 and all the actions are fully random. But the epsilon is reduced in each iteration and randomness in actions is also reduced. The graph for epsilon reduction linearly can be seen here.

Now while moving, depending on the state, it will start using the action with the maximum reward, that will be the desired action. The code snippet is as given below.
if self.learning==False:
action = random.choice(self.valid_actions)
print("Learning Disabled")
else:
if np.random.random() < self.epsilon:
action = random.choice(self.valid_actions)
print("Learning High Epsilon")
print(action)
else:
#print(self.get_maxQ(state))
#print(self.Q)
max=self.get_maxQ(state);
list=self.Q[state]
#print(list)
#print(list.keys()[list.values().index(max)])
action = list.keys()[list.values().index(max)]
print("Learning MaxQ")
print(action)
return action
epsilon is the probability, which will be decaying. So initially epsilon is always higher and thus the random action is taken. As the epsilon is decayed, the randomness is reduced and actions with max values are taken, and this how the car will start taking perfect actions as the time goes on. The results and the code for this is given below.

The 1st trial shows a random action with epsilon as high as 0.85. The actions are random and it can be seen that the car is penalized because of the wrong action it has taken.
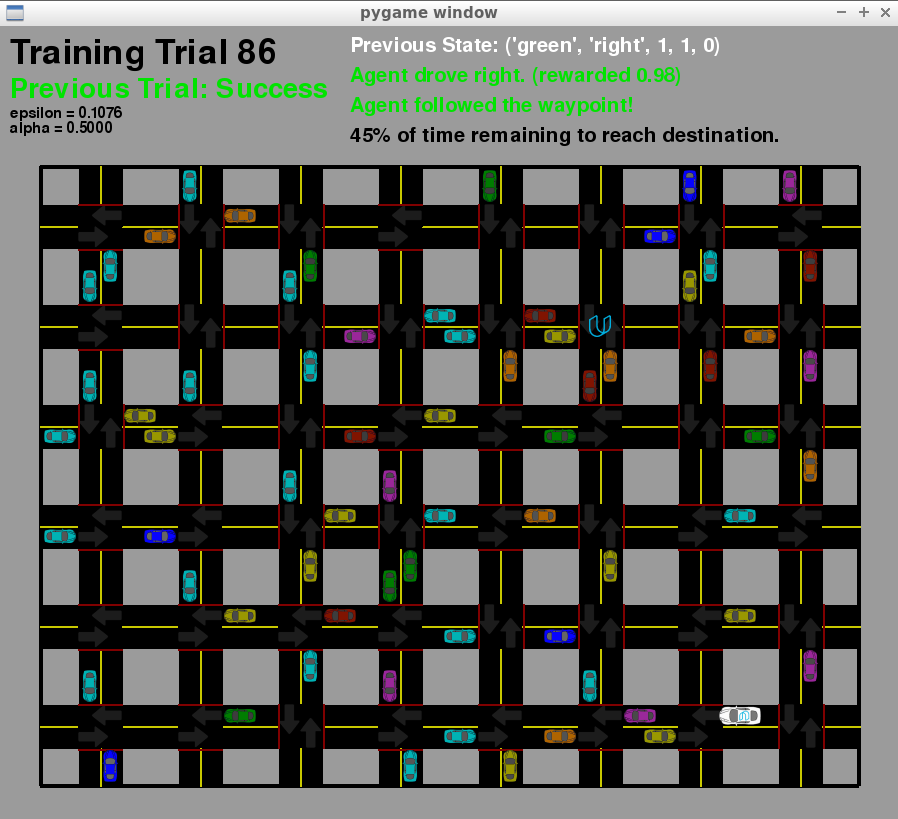
By the time it is 86th trial, the epsilon has been reduced to 0.1 and the actions are more determined by the previously explored Q-values. For the state that is green light with the waypoint pointing rightwards it drives to right perfectly.
This is just a simulated model, but it can be utilized with the actual system too with different states and different set of possible actions. The code for this can be found in my github repo by clicking here.
